Where billions of web pages compete for visibility, understanding how search engines discover and process content is fundamental to digital marketing success. Search engine crawling represents the critical first step in making your content discoverable online, yet many website owners and marketers overlook its significance. This comprehensive guide explores the intricate stages of search engine crawling, revealing how these sophisticated systems navigate the web to deliver relevant results to users worldwide.
Understanding Search Engine Crawling: The Foundation of Digital Discovery
Before diving into the stages, it’s essential to grasp what crawling in search engine operations actually means. Search crawling is the automated process by which search engines send out sophisticated programs, known as crawlers, bots, or spiders, to discover and analyze web content across the internet. These digital explorers systematically browse through websites, following links from one page to another, collecting information that will eventually determine whether your content appears in search results.
The crawling meaning in digital marketing extends far beyond simple discovery. It represents the gateway through which your carefully crafted content enters the consideration set of search engines. Without successful crawling, even the most brilliantly optimized content remains invisible to potential visitors. This makes understanding what is crawling in digital marketing absolutely critical for anyone seeking online visibility.
What’s the First Step in the Search Engine Process?
When someone asks “what’s the first step in the search engine” operation, the answer invariably points to crawling. The search engine process begins with discovering URLs through various methods: submitted sitemaps, links from other websites, and revisiting previously known pages. However, discovery alone doesn’t constitute crawling. The actual crawling stages begin when the search engine crawler decides to visit a URL and retrieve its content.
This initial discovery phase sets the foundation for everything that follows. Search engines maintain massive databases of known URLs, constantly updating this list as they encounter new links during their crawling activities. This interconnected web of discoveries creates a self-perpetuating cycle where each crawled page potentially leads to dozens more waiting to be explored.
Stage 1: URL Discovery and Queue Management
The first formal stage of search crawling involves identifying and prioritizing URLs for exploration. Search engine crawlers don’t randomly stumble upon websites; they follow a sophisticated process of URL discovery through multiple channels.
Major search engines maintain enormous queues of URLs awaiting exploration. These queues function like priority systems at airports, where certain pages receive expedited processing based on various factors. Fresh content from authoritative websites typically jumps to the front of the line, while pages with minimal updates or low perceived value might wait weeks or months for their turn.
During this stage, search engines consider several critical factors. The perceived importance of a domain, the frequency of content updates, and the number of quality backlinks all influence when and how often the search engine crawler visits a particular site. Websites that consistently publish valuable content and maintain strong link profiles find that major search engines can easily crawl their pages more frequently.
The URL discovery process also involves analyzing submitted XML sitemaps, which serve as roadmaps guiding crawlers to important pages. Smart webmasters leverage sitemaps to ensure their most valuable content receives priority attention during the crawling in search engine operations.
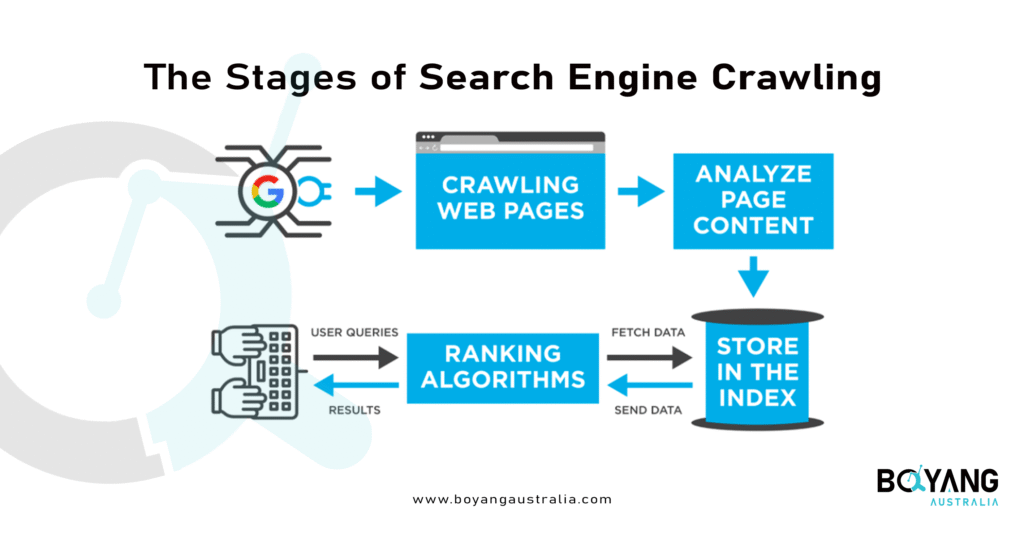
Stage 2: The Actual Crawl – Fetching and Processing Content
Once a URL reaches the front of the queue, the second stage begins: the actual page crawling operation. This is where how search engine crawler works becomes truly fascinating. The crawler sends an HTTP request to the web server hosting the target page, just like a regular browser would when you click a link.
However, what occurs when a search engine crawls a page differs significantly from human browsing. The crawler doesn’t see beautifully rendered designs or interactive elements in the same way users do. Instead, it receives the raw HTML code, CSS files, JavaScript, images, and other resources that comprise the page.
Modern crawlers have evolved considerably in how search engine crawlers work. They now execute JavaScript, rendering pages more like actual browsers to understand dynamic content. This advancement addresses the challenges posed by modern web development frameworks that rely heavily on client-side scripting.
During this fetching phase, the crawler respects the instructions provided in the robots.txt file, which functions as a set of rules specifying which pages or sections crawlers can and cannot access. This file plays a crucial role in crawlability meaning, as it directly impacts which portions of your site remain visible to search engines.
The crawler also examines the HTTP status codes returned by the server. A 200 status code signals success, while 404 indicates the page doesn’t exist, and 301 or 302 codes redirect the crawler to alternative URLs. These technical responses significantly influence the crawling stages and determine whether the crawler proceeds with processing the content.
Stage 3: Content Extraction and Analysis
After successfully fetching a page, the crawler enters the content extraction phase. This stage involves parsing the HTML to identify and extract meaningful information. The crawler systematically analyzes various elements: titles, headings, body text, meta descriptions, image alt attributes, and structured data markup.
Understanding what is crawling in seo requires recognizing that crawlers don’t simply download pages—they interpret them. They identify the primary content separate from navigation menus, advertisements, and boilerplate text. Advanced algorithms help distinguish between substantive content that addresses user queries and peripheral elements that provide site functionality.
During this extraction phase, the crawler also catalogs all the links found on the page. These discovered links feed back into the URL discovery queue, perpetuating the continuous cycle of crawling in digital marketing. Each link represents a potential pathway to undiscovered content, creating the interconnected structure that makes the web navigable.
The crawler assigns preliminary quality signals during this stage, evaluating factors like content uniqueness, readability, and relevance. While full ranking analysis happens later in the search engine process, initial quality assessments influence how thoroughly search engines explore a site’s deeper pages.
Stage 4: Resource Rendering and JavaScript Execution
In contemporary web development, many sites rely on JavaScript to display content dynamically. This creates unique challenges for crawling search engine operations, as traditional crawlers initially struggled with JavaScript-heavy websites.
Modern search engine crawlers have adapted by implementing a two-wave crawling approach. The first wave processes the basic HTML and identifies immediately accessible content. The second wave, which might occur minutes or hours later, executes JavaScript to render the page fully and discover content that appears only after scripts run.
This rendering stage has significant implications for crawled pages. Websites built entirely on JavaScript frameworks might experience delays in having their content fully indexed compared to sites with server-side rendering. Understanding this timing difference helps marketers optimize their technical architecture for better crawlability.
The rendering process also consumes substantial computational resources. Search engines allocate these resources carefully, meaning sites with strong authority and regular updates receive more generous rendering budgets. Smaller or newer sites might find that not every JavaScript element gets executed during each crawl, affecting what content ultimately gets processed.
Stage 5: Link Discovery and Relationship Mapping
As the crawler processes each page, it meticulously catalogs every link it encounters. This link discovery forms a crucial component of the crawling stages, as it determines how search engines navigate website hierarchies and understand content relationships.
Internal links guide crawlers through your site structure, revealing which pages you consider most important based on how prominently you link to them. Pages linked from the homepage or main navigation typically receive more frequent crawling search engine attention than those buried five clicks deep.
External links also play a vital role during this stage. When crawlers encounter outbound links, they add these destinations to their discovery queue, potentially leading them to entirely new domains. Conversely, inbound links from external sites signal to crawlers that your content deserves attention, often triggering more frequent visits.
The crawler creates a comprehensive map of these link relationships, understanding which pages cluster together topically and how authority flows through the link structure. This mapping directly influences the crawl and index process, as well-connected pages with strong internal linking patterns receive priority treatment.
Stage 6: Crawl Budget Allocation and Efficiency
Search engines don’t have unlimited resources, which brings us to the crucial concept of crawl budget. This represents the number of pages a search engine crawler will attempt to access on your site within a given timeframe. Understanding crawl budget proves essential for large websites with thousands or millions of pages.
Several factors influence crawl budget allocation. Website performance matters significantly—slow-loading pages consume more of the budget as crawlers wait for responses. Server errors or frequent downtime train crawlers to visit less often, assuming the site suffers from reliability issues.
Site popularity also impacts budget allocation. Websites that attract significant user traffic and backlinks signal their importance, earning larger crawl budgets. Conversely, small sites with minimal updates might only receive cursory attention, with crawlers visiting just a handful of pages during each session.
Technical optimization directly affects how efficiently you utilize your crawl budget. Eliminating duplicate content, fixing broken links, and creating clean URL structures ensure that crawlers spend their allocated time on valuable pages rather than wasting resources on problematic ones. This efficiency consideration makes crawlability meaning extend beyond mere accessibility to encompass smart resource utilization.
Stage 7: Respecting Crawl Rate and Server Capacity
Responsible crawling search engine operations include respecting server limitations. Crawlers implement rate limiting to avoid overwhelming websites with requests, which could slow down or crash servers and negatively impact user experience.
The crawl rate—how quickly a crawler makes requests to your server—adjusts dynamically based on your server’s response times. If your server responds quickly and reliably, crawlers may increase their request frequency. Conversely, if the server struggles or returns errors, crawlers slow down to avoid causing problems.
Website owners can influence crawl rates through settings in Google Search Console and similar tools, though search engines generally manage this automatically with sophisticated algorithms. Understanding how search engine crawlers work to protect server resources helps webmasters balance crawling thoroughness with performance considerations.
This stage highlights the reciprocal relationship between websites and search engines. While sites want comprehensive crawling for maximum visibility, they must also maintain server health. Search engines, meanwhile, aim to crawl thoroughly while acting as responsible web citizens that don’t degrade the infrastructure they depend on.
Stage 8: Data Packaging and Transfer to Indexing
After completing the crawling and analysis phases, crawlers package the extracted data for transfer to the indexing system. This transition from crawling to indexing represents a critical handoff in the broader search engine process.
The crawler compiles everything it learned about the page: the textual content, metadata, link relationships, page structure, and preliminary quality signals. This comprehensive data package moves into the indexing pipeline, where different systems analyze it further and determine whether and how to include the page in search results.
Not all crawled pages make it to the index. Search engines employ quality filters during and after crawling that can exclude pages deemed duplicative, low-quality, or manipulative. This explains why page crawling doesn’t guarantee visibility—crawling is necessary but not sufficient for ranking in search results.
Understanding the distinction between crawling and indexing proves essential for troubleshooting visibility issues. A page might be successfully crawled but excluded from the index due to content quality concerns, canonical tags pointing elsewhere, or noindex directives. Webmasters must verify both crawling and indexing status when diagnosing search visibility problems.
Stage 9: Continuous Re-Crawling and Fresh Content Discovery
Search engine crawling isn’t a one-time event but a continuous cycle. After completing an initial crawl of your site, search engine crawlers return periodically to check for updates, new content, and changes to existing pages.
Re-crawling frequency depends on numerous factors. News websites publishing breaking content might receive crawl visits every few minutes, ensuring fresh stories appear rapidly in results. Corporate sites with static information might only see crawlers weekly or monthly. Understanding these patterns helps marketers time content publication for maximum impact.
Certain signals trigger increased crawling attention. Publishing new content, acquiring fresh backlinks, and experiencing traffic surges all suggest to search engines that your site deserves more frequent monitoring. Strategic content calendars that maintain consistent publishing schedules help train crawlers to check back regularly.
The freshness factor particularly matters for time-sensitive queries. When users search for current events or recently developing topics, search engines prioritize recently crawled pages over older content. This creates competitive advantages for sites that maintain active publishing schedules and ensure major search engines can easily crawl their latest additions.
Stage 10: Crawl Error Detection and Reporting
The final stage involves detecting and reporting crawl errors back to webmasters. Modern search engines provide comprehensive tools like Google Search Console that detail crawling issues encountered during the search crawl process.
Common crawl errors include server errors (5xx status codes), page not found errors (404s), robots.txt blocking, and redirect chains that slow crawling efficiency. Identifying these issues helps webmasters improve their site’s crawlability, ensuring that valuable content doesn’t remain hidden due to technical problems.
Monitoring crawl statistics reveals patterns in how search engines interact with your site. Sudden drops in crawled pages might indicate technical problems or server issues. Increases in crawl errors suggest recent changes introduced problems. These insights transform raw crawling data into actionable intelligence for technical SEO improvements.
Webmasters should regularly review crawl reports, addressing errors systematically to maximize the effectiveness of allocated crawl budgets. Fixing broken links, resolving server errors, and eliminating redirect chains ensures that when the search engine crawler visits, it successfully accesses and processes valuable content rather than encountering obstacles.
The Role of Crawling in Modern Digital Marketing Strategy
Understanding what is crawling in seo and how it fits within broader digital marketing strategy proves increasingly vital as competition for online visibility intensifies. Crawling represents the first domino in a chain reaction that determines whether content reaches intended audiences.
Effective crawling optimization intersects with multiple marketing disciplines. Technical SEO specialists ensure crawler access through proper site architecture and robots.txt configuration. Content marketers create compelling material worthy of being crawled and indexed. Web developers implement crawl-friendly technologies that balance user experience with search engine accessibility.
The crawling meaning in digital marketing extends to competitive advantage. Organizations that master crawl optimization often outperform competitors who neglect these technical foundations. When major search engines can easily crawl your site, you’re positioned to capture visibility opportunities more quickly and comprehensively than rivals struggling with crawlability issues.
Best Practices for Optimizing Search Engine Crawling
Implementing strategic improvements to how search engines crawl your site requires attention to multiple factors. Start by creating and maintaining an XML sitemap that prioritizes your most important pages. Submit this sitemap through search console tools to facilitate efficient URL discovery.
Optimize your robots.txt file carefully, blocking only genuinely unnecessary sections like admin areas or duplicate content parameters. Overly restrictive robots.txt files inadvertently prevent crawling of valuable pages, shooting yourself in the foot before the race begins.
Implement a clean URL structure that logically organizes content and avoids excessive parameters. Search engine crawlers navigate structured sites more efficiently, allocating more of your crawl budget to substantive pages rather than navigating confusing architectures.
Improve server response times through performance optimization. Fast-loading pages allow crawlers to process more content within their allocated time, improving overall crawling thoroughness. Monitor server logs to identify when crawlers visit and ensure adequate resources during peak crawling periods.
Establish strong internal linking that connects related content and ensures no page sits orphaned without links pointing to it. Well-linked pages receive more frequent crawling attention and benefit from the link equity flowing through your site structure.
Conclusion
The stages of search engine crawling represent far more than technical minutiae—they form the essential foundation upon which all search visibility builds. From initial URL discovery through content extraction, rendering, and eventual handoff to indexing systems, each stage presents opportunities for optimization and potential pitfalls to avoid.
Understanding how search engine crawlers work empowers marketers and website owners to make informed decisions about site architecture, content strategy, and technical implementation. When you comprehend what occurs when a search engine crawls your site, you can proactively address issues rather than reactively troubleshooting visibility problems.
The crawling in digital marketing landscape continues evolving as search engines become more sophisticated and websites employ increasingly complex technologies. Staying informed about crawling best practices and regularly auditing your site’s crawlability ensures you maintain the technical foundation necessary for sustained search visibility.
Ultimately, successful digital marketing in search channels begins with ensuring that search engines can discover, access, and understand your content. Master the crawling stages, and you’ve laid the groundwork for everything that follows in the competitive quest for search visibility and organic traffic growth. You can achieve these all with Boyang Austalia. Contact us today for 360 SEO solutions and free SEO audit report.




